词法分析 |Python 实现LL(1) 文法
文法如下:
文法:
1: lexp -> atom | list
2: atom -> number | identifier
3: list -> (lexp-seq)
4: lexp-seq -> lexp seq2
5: seq2 -> lexp seq2 | ε
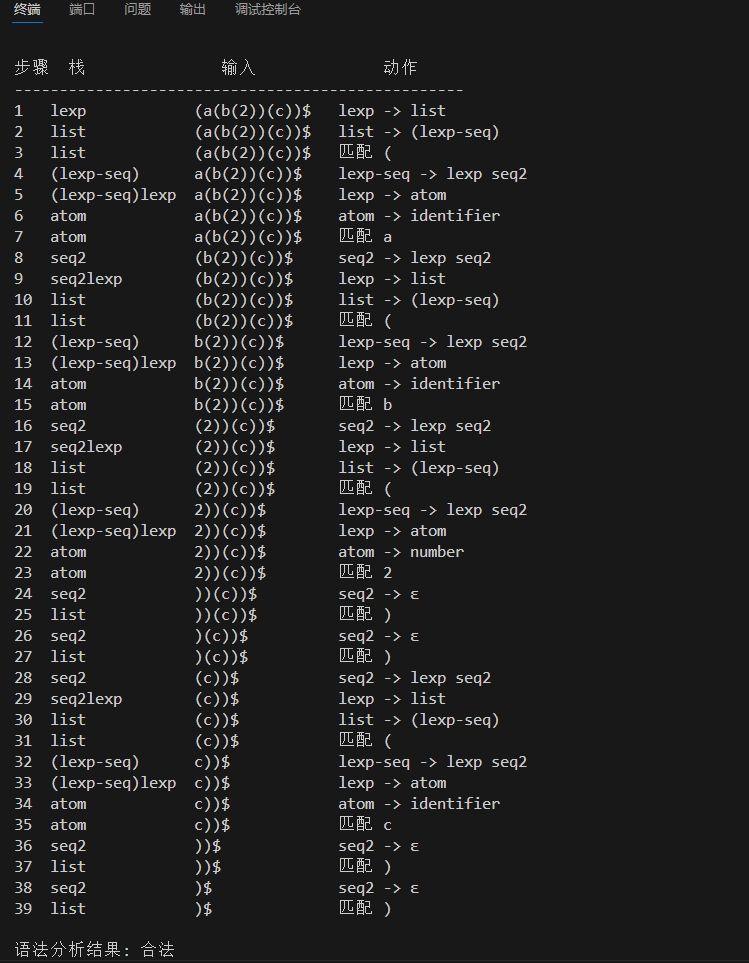
需要判断是字符串为(a(b(2))(c)) 并且输出详细的步骤
'''
文法:
1: lexp -> atom | list
2: atom -> number | identifier
3: list -> (lexp-seq)
4: lexp-seq -> lexp seq2
5: seq2 -> lexp seq2 | ε
'''
# Token类型
TOKEN_NUMBER = 'NUMBER' # number
TOKEN_IDENTIFIER = 'IDENTIFIER' # identifier
TOKEN_LPAREN = 'LPAREN' # (
TOKEN_RPAREN = 'RPAREN' # )
TOKEN_EOF = 'EOF' # 结束符
class Token:
def __init__(self, type, value=None):
self.type = type # 类型
self.value = value # 值
class Lexer:
def __init__(self, text):
self.text = text # 输入文本
self.pos = 0
self.current_char = self.text[self.pos] if text else None
def error(self):
raise Exception('词法分析错误')
def advance(self):
self.pos += 1 # 移动到下一个字符
if self.pos > len(self.text) - 1:
self.current_char = None # 到达末尾
else:
self.current_char = self.text[self.pos] # 更新当前字符
def skip_whitespace(self):
while self.current_char and self.current_char.isspace():
self.advance() # 跳过空白字符
def number(self):
result = ''
while self.current_char and self.current_char.isdigit():
result += self.current_char
self.advance()
return int(result) # 返回整数
def identifier(self):
result = ''
while self.current_char and self.current_char.isalnum():
result += self.current_char
self.advance()
return result # 返回标识符
def get_next_token(self):
while self.current_char:
if self.current_char.isspace():
self.skip_whitespace() # 跳过空白字符
continue
if self.current_char.isdigit():
return Token(TOKEN_NUMBER, self.number()) # 返回数字
if self.current_char.isalpha():
return Token(TOKEN_IDENTIFIER, self.identifier()) # 返回标识符
if self.current_char == '(':
self.advance()
return Token(TOKEN_LPAREN, '(') # 返回左括号
if self.current_char == ')':
self.advance()
return Token(TOKEN_RPAREN, ')') # 返回右括号
self.error()
return Token(TOKEN_EOF) # 返回结束符
class Parser:
def __init__(self, lexer):
self.lexer = lexer
self.current_token = self.lexer.get_next_token()
self.step = 1 # 添加步骤计数
# 构建First集
self.FIRST = {
'lexp': {TOKEN_NUMBER, TOKEN_IDENTIFIER, TOKEN_LPAREN}, # lexp -> atom | list
'atom': {TOKEN_NUMBER, TOKEN_IDENTIFIER}, # atom -> number | identifier
'list': {TOKEN_LPAREN}, # list -> (lexp-seq)
'lexp-seq': {TOKEN_NUMBER, TOKEN_IDENTIFIER, TOKEN_LPAREN}, # lexp-seq -> lexp seq2
'seq2': {TOKEN_NUMBER, TOKEN_IDENTIFIER, TOKEN_LPAREN, 'ε'} # seq2 -> lexp seq2 | ε
}
# 构建Follow集
self.FOLLOW = {
'lexp': {TOKEN_RPAREN, TOKEN_EOF, TOKEN_NUMBER, TOKEN_IDENTIFIER, TOKEN_LPAREN}, # lexp -> atom | list
'atom': {TOKEN_RPAREN, TOKEN_EOF, TOKEN_NUMBER, TOKEN_IDENTIFIER, TOKEN_LPAREN}, # atom -> number | identifier
'list': {TOKEN_RPAREN, TOKEN_EOF, TOKEN_NUMBER, TOKEN_IDENTIFIER, TOKEN_LPAREN}, # list -> (lexp-seq)
'lexp-seq': {TOKEN_RPAREN}, # lexp-seq -> lexp seq2
'seq2': {TOKEN_RPAREN} # seq2 -> lexp seq2 | ε
}
# 构建预测分析表
self.PREDICT = {
('lexp', TOKEN_NUMBER): 'atom', # lexp -> atom
('lexp', TOKEN_IDENTIFIER): 'atom', # lexp -> atom
('lexp', TOKEN_LPAREN): 'list', # lexp -> list
('atom', TOKEN_NUMBER): 'number', # atom -> number
('atom', TOKEN_IDENTIFIER): 'identifier', # atom -> identifier
('list', TOKEN_LPAREN): '(lexp-seq)',
('lexp-seq', TOKEN_NUMBER): 'lexp seq2', # lexp-seq -> lexp seq2
('lexp-seq', TOKEN_IDENTIFIER): 'lexp seq2', # lexp-seq -> lexp seq2
('lexp-seq', TOKEN_LPAREN): 'lexp seq2', # lexp-seq -> lexp seq2
('seq2', TOKEN_NUMBER): 'lexp seq2', # seq2 -> lexp seq2
('seq2', TOKEN_IDENTIFIER): 'lexp seq2', # seq2 -> lexp seq2
('seq2', TOKEN_LPAREN): 'lexp seq2', # seq2 -> lexp seq2
('seq2', TOKEN_RPAREN): 'ε' # seq2 -> ε
}
def predict(self, non_terminal):
"""使用预测分析表进行分析"""
key = (non_terminal, self.current_token.type)
if key not in self.PREDICT:
self.error()
return self.PREDICT[key]
def error(self):
raise Exception('语法分析错误')
def eat(self, token_type, stack=''):
if self.current_token.type == token_type:
# 显示终结符匹配
remaining_input = self.get_remaining_input()
match_str = f"匹配 {self.current_token.value}" if self.current_token.value else f"匹配 {token_type}"
self.print_step(stack, remaining_input, match_str)
self.current_token = self.lexer.get_next_token()
else:
self.error()
def print_step(self, stack, input_str, action):
"""打印当前分析步骤"""
# 只保留栈的最后一个非终结符
stack_parts = stack.split()
short_stack = stack_parts[-1] if stack_parts else ''
# 缩短输入显示,只显示前15个字符
short_input = input_str[:15] + ('...$' if len(input_str) > 15 else '')
print(f"{self.step:<3} {short_stack:<15} {short_input:<15} {action}")
self.step += 1
def get_remaining_input(self):
"""获取剩余输入"""
pos = self.lexer.pos - 1 if self.current_token.type != TOKEN_EOF else self.lexer.pos
return self.lexer.text[pos:] + '$'
# lexp -> atom | list
def lexp(self, stack=''):
current_stack = f"{stack}lexp"
remaining_input = self.get_remaining_input()
production = self.predict('lexp')
if production == 'atom':
self.print_step(current_stack, remaining_input, 'lexp -> atom')
self.atom(current_stack)
elif production == 'list':
self.print_step(current_stack, remaining_input, 'lexp -> list')
self.list(current_stack)
else:
self.error()
# atom -> number | identifier
def atom(self, stack=''):
current_stack = f"{stack} atom"
remaining_input = self.get_remaining_input()
if self.current_token.type == TOKEN_NUMBER:
self.print_step(current_stack, remaining_input, 'atom -> number')
self.eat(TOKEN_NUMBER, current_stack) # 传入当前栈
elif self.current_token.type == TOKEN_IDENTIFIER:
self.print_step(current_stack, remaining_input, 'atom -> identifier')
self.eat(TOKEN_IDENTIFIER, current_stack) # 传入当前栈
else:
self.error()
# list -> (lexp-seq)
def list(self, stack=''):
current_stack = f"{stack} list"
remaining_input = self.get_remaining_input()
self.print_step(current_stack, remaining_input, 'list -> (lexp-seq)')
self.eat(TOKEN_LPAREN, current_stack) # 传入当前栈
self.lexp_seq(current_stack)
self.eat(TOKEN_RPAREN, current_stack) # 传入当前栈
# lexp-seq -> lexp seq2
def lexp_seq(self, stack=''):
current_stack = f"{stack} (lexp-seq)"
remaining_input = self.get_remaining_input()
self.print_step(current_stack, remaining_input, 'lexp-seq -> lexp seq2')
self.lexp(current_stack)
self.seq2(current_stack)
# seq2 -> lexp seq2 | ε
def seq2(self, stack=''):
current_stack = f"{stack} seq2"
remaining_input = self.get_remaining_input()
production = self.predict('seq2')
if production == 'lexp seq2':
self.print_step(current_stack, remaining_input, 'seq2 -> lexp seq2')
self.lexp(current_stack)
self.seq2(current_stack)
elif production == 'ε':
self.print_step(current_stack, remaining_input, 'seq2 -> ε')
return
else:
self.error()
def parse(self):
print(f"{'步骤':<3} {'栈':<15} {'输入':<15} {'动作'}")
print("-" * 50)
self.lexp()
if self.current_token.type != TOKEN_EOF:
self.error()
return True
def main():
# 测试用例
test = "(a(b(2))(c))"
print(f"\n分析输入: {test}\n")
try:
lexer = Lexer(test)
parser = Parser(lexer)
result = parser.parse()
print("\n语法分析结果: 合法")
except Exception as e:
print(f"\n语法分析结果: 不合法 ({str(e)})")
if __name__ == '__main__':
main()
执行效果